正则 : 模式
qidu 2020-07-05
1. 模式
1.0 回溯
贪婪模式和懒惰模式都会进行回溯;
匹配两次相关的字符时,匹配到不符合要求的字符后,这个字符才算匹配完,然后继续匹配下一个字符;
比如:xy{1,3}z
样本:xyyyz
在匹配该样本时,无论贪婪模式还是懒惰模式,都需要匹配到z后才能知道y字符匹配完成,才会继续匹配表达式中的z字符1.1 贪婪模式
默认模式就是贪婪模式,正则会在满足要求的情况下尽可能多的匹配字符知道匹配到不符合要求的字符为止;

1.2 懒惰模式
在满足要求的情况下尽可能多的匹配字符知道匹配到不符合要求的字符为止; 在量词后加?即表示懒惰模式

1.3 独占模式
在满足要求的情况下尽可能多的匹配字符,如果匹配失败就结束; 在量词后加+即表示独占模式

2. 匹配模式
通过模式修饰符(?模式符号)来表示正则的匹配模式,使用时将执行的模式修饰符放在指定的正则前面即可。
2.1 不区分大小写
(?i),Insensitive : 不敏感 所有字符不区分大小写,在正则最前面添加(?i)即可

部分字符不区分大小写,在需要不区分大小写的部分添加(?i),再用()将这部分括起来 ((?i)baby)Come 表示 baby 不区分大小写, Come 区分大小写 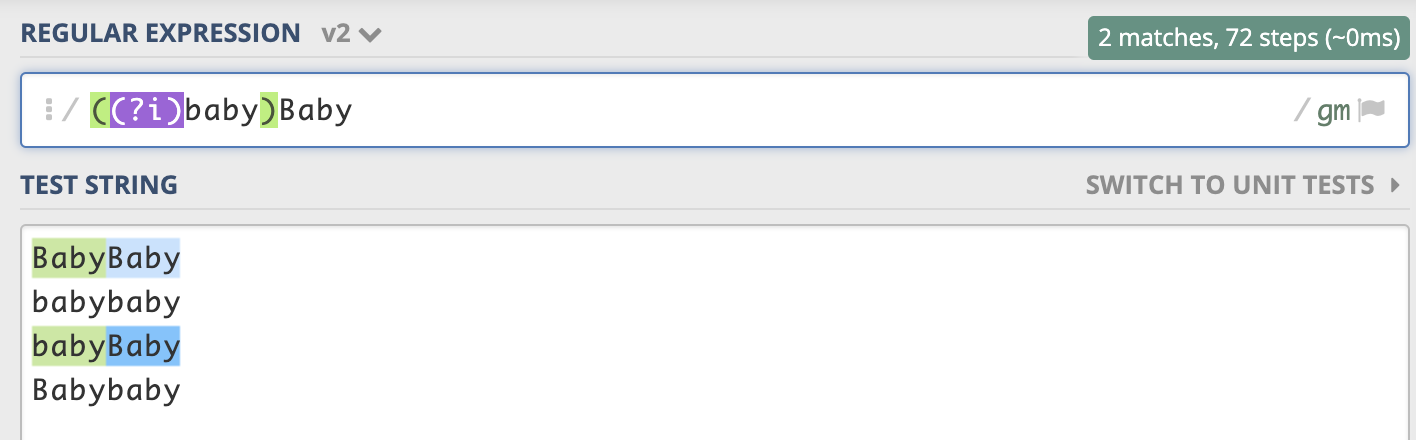 不区分大小写,但是第二次匹配的格式与第一次一致 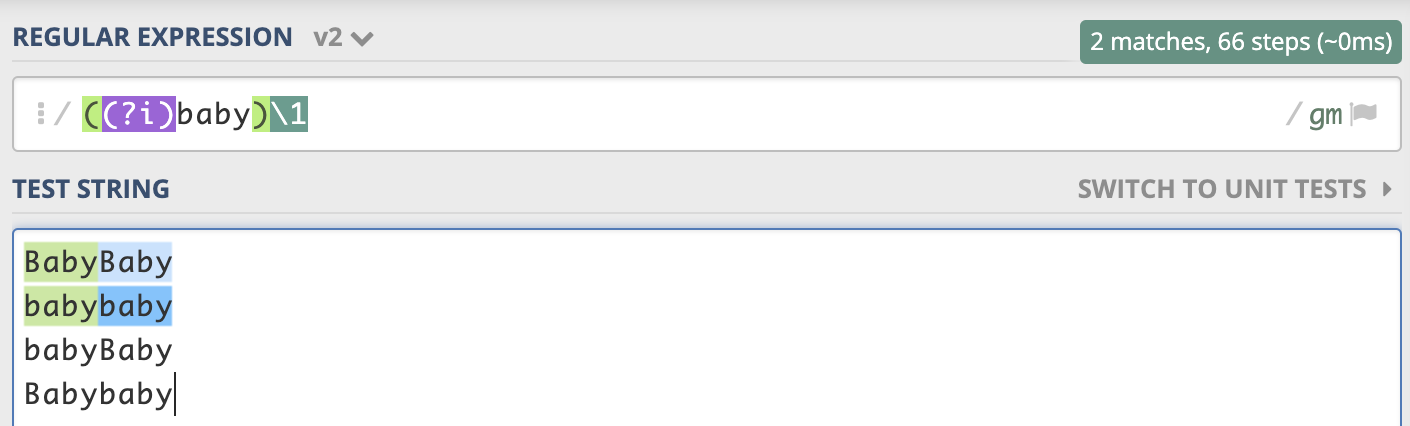
2.2 点号通配模式
*可以匹配所有字符,包括换行符
2.3 多行匹配模式
默认情况下,^匹配整个文本的开头,$匹配整个文本的结尾

(?m), 表示多行匹配模式,会匹配每一行的开头和结尾

2.4 注释模式
给正则表达式添加注释 (?w comment)


相关推荐
杨德龙 0喜欢 / 0评论 2020-11-11
不要皱眉 0喜欢 / 5评论 2020-10-14
满地星辰 0喜欢 / 0评论 2020-09-16
梦的天空 0喜欢 / 0评论 2020-08-25
lrjnlp 0喜欢 / 0评论 2020-07-19
flyingssky 0喜欢 / 0评论 2020-07-05
flyingssky 0喜欢 / 0评论 2020-06-27
RuoShangM 0喜欢 / 0评论 2020-06-17
天高任鸟飞 0喜欢 / 0评论 2020-06-13
Darklovy 0喜欢 / 0评论 2020-06-11
qidu 0喜欢 / 0评论 2020-06-08
Darklovy 0喜欢 / 0评论 2020-06-07
jyj00 0喜欢 / 0评论 2020-06-06
flyingssky 0喜欢 / 0评论 2020-06-04
山水沐光 0喜欢 / 0评论 2020-05-26
山水沐光 0喜欢 / 0评论 2020-05-25
Buerzhu 0喜欢 / 0评论 2020-05-17
zjcheerup 0喜欢 / 0评论 2020-05-14
gaohuirong0 0喜欢 / 0评论 2020-04-08
Hwaphon 0喜欢 / 0评论 2020-04-08
NBkiller 0喜欢 / 0评论 2020-04-08
鹤啸九天 0喜欢 / 0评论 2020-04-08
Darklovy 0喜欢 / 0评论 2020-05-11
eroshn 0喜欢 / 0评论 2020-05-11
luofuIT成长记录 0喜欢 / 0评论 2020-05-09
modaiairen 0喜欢 / 0评论 2020-05-05
Buerzhu 0喜欢 / 0评论 2020-05-01
RuoShangM 0喜欢 / 0评论 2020-05-01
fetten 0喜欢 / 0评论 2020-04-15
jyj00 0喜欢 / 0评论 2020-03-08
wangqing 0喜欢 / 0评论 2020-03-06
Buerzhu 0喜欢 / 0评论 2020-03-05
leap 0喜欢 / 0评论 2020-03-03
白马王 0喜欢 / 0评论 2020-02-22
gaohuirong0 0喜欢 / 0评论 2020-02-27
wyq 0喜欢 / 0评论 2020-02-05
jyj00 0喜欢 / 0评论 2020-02-19
herogood 0喜欢 / 0评论 2020-02-19
eroshn 0喜欢 / 0评论 2020-01-24
jyj00 0喜欢 / 0评论 2020-01-11
RuoShangM 0喜欢 / 0评论 2020-01-11
luofuIT成长记录 0喜欢 / 0评论 2020-01-08
oXiaoChong 0喜欢 / 0评论 2020-01-08
luofuIT成长记录 0喜欢 / 0评论 2020-01-08
oXiaoChong 0喜欢 / 0评论 2020-01-07
CloudXli 0喜欢 / 0评论 2020-01-04